Apache Kafka: How It Actually Works
Most people encounter Kafka through job postings or architecture diagrams where it sits between everything. Someone always calls it a message queue. It's not: and that distinction matters for how you reason about it.
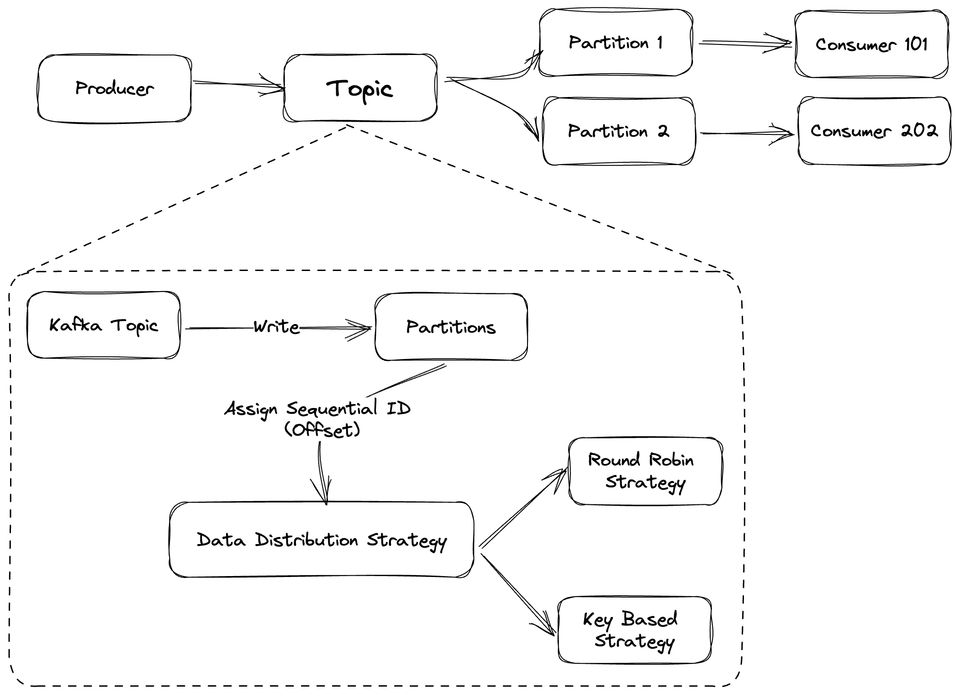
Kafka is a distributed event log. Producers write to topics, consumers read from them, but unlike a queue, nothing gets deleted when a consumer reads it. The data stays on disk until the retention window expires. That single design decision changes the entire mental model.
It's Not a Message Queue
Traditional queues (RabbitMQ, SQS) work on a delivered-then-gone model. Kafka doesn't. Every event gets written to a partition, an append-only, ordered log on disk: and consumers track their own position in that log via an offset. If you screw up your consumer logic and process 10,000 events wrong, you can reset the offset and replay them. Try doing that with SQS.
This also means multiple independent consumer groups can read the same data simultaneously. Your analytics pipeline and your notification service can both consume the same order events without either knowing the other exists. Total decoupling.
The Partition Is the Unit of Everything
Topics are logical. Partitions are physical. A topic gets split across N partitions, distributed across brokers. More partitions means more parallelism, you can have one consumer per partition reading simultaneously.
The key routing behavior is what makes ordering guarantees possible: if you send a message with a key, Kafka always routes it to the same partition. All events for user_id=123 land in order on the same partition. That's how you get sequential processing without a distributed lock.
Consumers track their position using an offset, a sequential ID per record in the partition. If your consumer crashes, it restarts from the last committed offset. This gives you at-least-once delivery, so your consumer logic needs to be idempotent.
The Acks Setting That Will Eventually Bite You
Producer acknowledgements control how safe your writes actually are:
• acks=0: fire and forget. Fast. You will lose data.
• acks=1: leader confirms the write before replicas have copied it. This is the default. It's also the reason behind most Kafka data loss stories I've heard. Leader dies between write and replication: gone.
• acks=all: every in-sync replica confirms. Adds latency, but it's the only setting that actually means your data is safe.
The default being acks=1 is a quiet foot-gun you need to be aware of before you put anything critical through Kafka.
Retention Is a Balancing Act
You can configure Kafka to hold data for a time window or up to a size limit, whichever triggers first wins. Unread messages get deleted just the same as read ones. Store too long and disk fills fast on busy topics. Huge logs also make broker recovery painful when a node dies, because the new leader has to catch up on everything.
Compacted topics are a different mode: instead of deleting by time, Kafka keeps the most recent value per key indefinitely. Useful for state changelogs. It's the feature that makes people ask if Kafka is a database. It isn't, but it blurs the line.
The Bottom Line
Kafka earns its complexity when you need high throughput, event replay, or fan-out to multiple independent consumers. Once we moved to it for our event pipeline, the decoupling alone was worth it: services stopped needing to know about each other.
The operational cost is real though. Partition counts, replication factors, retention tuning, disk monitoring: all of it requires thought. Managed options like Confluent Cloud or AWS MSK exist for a reason. If you just need a simple task queue, Kafka is overkill. But if you're building something where events need to be replayable, auditable, or consumed by multiple systems, it's the right tool.