Ring Buffers vs. Double-Ended Linked Lists
Not every data structure decision needs a framework. Sometimes it's just: do I need a fixed-size, cache-friendly loop, or a dynamic list I can grow? Ring buffers and doubly linked lists are the two ends of that tradeoff.
Ring Buffers: A Circular Dance
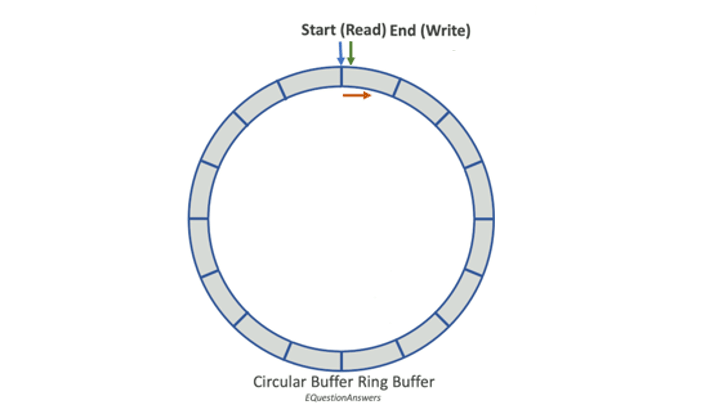
A ring buffer is a fixed-size chunk of memory where the last slot wraps back to the first, forming a loop. Producers write to the tail, consumers read from the head. When it fills up, the oldest data gets overwritten: no allocation, no deallocation, just pointer arithmetic.
Key properties:
- Fixed-size: capacity is set at creation and never changes
- Overwrites on full: new data pushes out the oldest
- Fast: add/remove is O(1), no memory management involved
The fixed-size constraint is the point, not a limitation. It gives you predictable memory usage and keeps access patterns cache-friendly.
Double-Ended Linked Lists: The Two-Way Street
A doubly linked list is the opposite trade. Each node carries data plus two pointers, one to the previous node, one to the next. You can insert or remove from either end in O(1), and the list grows or shrinks dynamically as needed.
Key properties:
- Dynamic size: grows and shrinks on demand
- No overwriting: nodes are created and freed as needed
- Slower in practice: each node is a separate heap allocation
The flexibility is real, but you pay for it in allocation overhead and pointer chasing, not ideal when you need predictable, low-latency access.
Our Use Case
We needed fast, fixed-size storage to keep track of recent activity. The priorities were clear: predictable latency, minimal allocation, high throughput. Ring buffer was the obvious call.
Here's the Go implementation we landed on:
type CircularBuffer[T any] struct {
buffer []T
size int
head int
tail int
count int
mu sync.RWMutex
}
// NewCircularBuffer constructor
func New[T any](size int) *CircularBuffer[T] {
return &CircularBuffer[T]{
buffer: make([]T, size),
size: size,
head: 0,
tail: 0,
count: 0,
}
}
// Add new item to the circular buffer's tail
func (cb *CircularBuffer[T]) Add(item T) {
cb.mu.Lock()
defer cb.mu.Unlock()
cb.buffer[cb.tail] = item
cb.tail = (cb.tail + 1) % cb.size
if cb.count < cb.size {
cb.count++
} else {
cb.head = (cb.head + 1) % cb.size
}
}
// GetRecent items from the buffer
func (cb *CircularBuffer[T]) GetRecent(count int) []T {
cb.mu.RLock()
defer cb.mu.RUnlock()
result := make([]T, 0, count)
elements := 0
startIndex := (cb.tail - 1 + cb.size) % cb.size
for i := startIndex; elements < count && elements < cb.count; i = (i - 1 + cb.size) % cb.size {
result = append(result, cb.buffer[i])
elements++
}
return result
}The Bottom Line
If you know your upper bound and need predictable performance, ring buffers win. If you need dynamic sizing or bidirectional traversal and can absorb the allocation cost, doubly linked lists are the right tool. Most of the time the constraints of your use case make the choice obvious, you just have to know what you're optimizing for.